



Introduction
Database design is where most “simple apps” either stay simple or quietly become a mess. If the structure is solid, you can add features for years without constantly reworking your data. If the structure is shaky, everything gets harder: reporting, permissions, automation, imports, performance, and even basic fixes.
This guide is practical. You will get a clear process, proven patterns, and copy ready examples you can adapt for real systems. At the end, you will also see how to translate the same database design concepts into a Tadabase build.
Quick checklist
Use this as a pre launch database review.
- Every table has one job. If a table mixes two different “things,” split it.
- Every record has a stable ID. Use an internal primary key, not a name or email.
- Relationships are explicit. One to many and many to many are modeled correctly.
- No duplicated source of truth. If a value can be derived, derive it.
- Status fields are standardized. Avoid 12 similar statuses across tables.
- Dates are unambiguous. Created at, updated at, and key business dates are consistent.
- Reporting knows where to look. The design supports the dashboards you will need later.
- Permissions align to structure. You can restrict access cleanly by team, client, or role.
- Imports have a plan. You know what the “matching key” is for each entity.
What database design is
Database design is the work of structuring data so it can be stored, managed, and retrieved reliably. In practice, that means choosing the right tables, defining fields, and setting up relationships so your app works the way the business works. Most “database design diagrams” exist to make those relationships and responsibilities visible before you build.
If you only remember one thing, remember this: database design is a product decision. It determines what your system can do quickly, what it can do safely, and what it will cost you later in rework.
A step by step database design process
A simple process consistently beats cleverness. This approach works for small internal tools and for large production systems.
Step 1: Define the purpose
- What does the system need to track
- What outcomes does it need to produce
- Who uses it and what do they need to see
Step 2: List the “things” you are tracking
These become your candidates for tables. Examples: Customers, Locations, Employees, Projects, Orders, Invoices, Appointments, Tickets.
Step 3: Turn each “thing” into a table
Do not overthink the first pass. Create one table per real entity. You can refine and normalize after you see the relationships.
Step 4: Define fields for each table
Start with what you actually need to run the workflow. Avoid fields that only exist “just in case” unless you already know the report or automation that will rely on them.
Step 5: Choose a primary key for every table
Every record needs a stable identifier. In most systems, that is an internal ID. Do not use a name, an email, or an invoice number as the primary key. Those change, and you will regret it.
Step 6: Model relationships
Ask “how many” on each side:
- One customer can have many orders
- One project can have many tasks
- Many users can belong to many workspaces
Step 7: Refine and apply normalization rules
Refinement is where quality comes from: removing duplication, tightening responsibilities, and ensuring relationships match reality. Normalization is part of this step, but do it with intention.
This process is commonly taught as a sequence that starts with purpose, organizes information into tables and columns, sets keys and relationships, and then refines the design and applies normalization rules.
Core concepts that make designs work
Entities and attributes
An entity is a “thing” you track (table). Attributes are the properties of that thing (fields). Example: Customers (entity) has Name, Email, Status (attributes).
Primary keys
A primary key uniquely identifies each record in a table. Best practice is a non meaningful internal ID, so it never changes.
Foreign keys
A foreign key is how one table references another table. Example: Orders table stores CustomerID to link each order to the customer who placed it.
Constraints and validation
Constraints protect data integrity. Even if your platform abstracts the database layer, you still want the same discipline: required fields, valid formats, controlled options, and consistent relationships.
Relationship patterns you will use constantly
One to many
Example: One customer has many orders.
- Customers table has CustomerID
- Orders table includes CustomerID (foreign key)
Many to many using a join table
Many to many is where people break databases. You almost always model it with a join table.
Example: Users and Projects
- Users
- Projects
- ProjectMembers join table with UserID and ProjectID (and often Role, AddedAt)
One to one
One to one is less common than people think. Use it when a record has an optional “extension” that should not bloat the main table.
Example: Employees and EmployeePrivateInfo
Normalization explained with a real example
Normalization reduces duplication and keeps updates safe. Instead of storing the same fact in ten places, you store it once and reference it.
A common bad design
Imagine an Orders table that stores customer name, email, and phone on every order. That feels convenient until the customer updates their email and now your database has 14 different versions of the truth.
A normalized design
- Customers stores Name, Email, Phone
- Orders stores CustomerID and order specific fields
Normalization cheat sheet
- 1NF Each field holds one value. No comma separated lists in a single field.
- 2NF Fields depend on the whole key (relevant when you have composite keys in join tables).
- 3NF Fields depend on the key, not on other non key fields (avoid indirect duplication).
Normalization is a tool, not a religion. If you denormalize for performance or reporting, do it on purpose and document it.
Relational vs NoSQL decisions
Relational databases are a strong default when your system has structured data and real relationships: customers, transactions, inventory, scheduling, compliance workflows, and most internal systems.
NoSQL approaches can be a fit when your data is highly variable, document like, or extremely write heavy, such as logs, event streams, and some content systems.
| Decision factor | Relational design | NoSQL design |
|---|---|---|
| Relationships matter | Strong fit | Often manual or embedded |
| Schema changes | Structured changes | More flexible |
| Reporting and joins | Strong fit | Can be harder depending on model |
| Typical use cases | CRMs, ops systems, finance, inventory | Logs, events, content documents, IoT |
Tadabase is built for structured, relational database design so you can model real workflows, relationships, and permissions cleanly.
Performance and scale without redesigns
You do not need to be a database engineer to design for performance. You just need to avoid the mistakes that force expensive work later.
Design with your most common queries in mind
- What will users search most often
- What lists will be filtered by status, owner, date, or client
- What dashboards will run daily
Avoid wide “everything tables”
When one table tries to hold every possible field, you get slow UI, confusing data entry, and fragile reporting. If fields only apply to one subtype, consider a related detail table.
Use join tables for many to many
This improves correctness and makes reporting possible without hacks. It also makes permissions easier because membership can live in one place.
Keep history as history
If you need an audit trail, do not overwrite important fields. Store changes as separate records: status history, assignment history, billing history.
Common database design mistakes
Storing lists in one field
If a field contains “A, B, C”, you just made reporting, filtering, and permissions harder. Use a related table instead.
Duplicating “current state” across tables
If CustomerStatus lives in Customers and also in Orders and also in Tickets, you will eventually get mismatches. Pick one source of truth.
Using natural keys as your primary ID
Invoice numbers change. Emails change. Names change. Use an internal ID.
Over normalizing early
Normalization is good, but do not split everything into tiny tables before you understand how the app will be used. Build the first clean version, then normalize what is clearly duplicated.
Database design examples you can copy
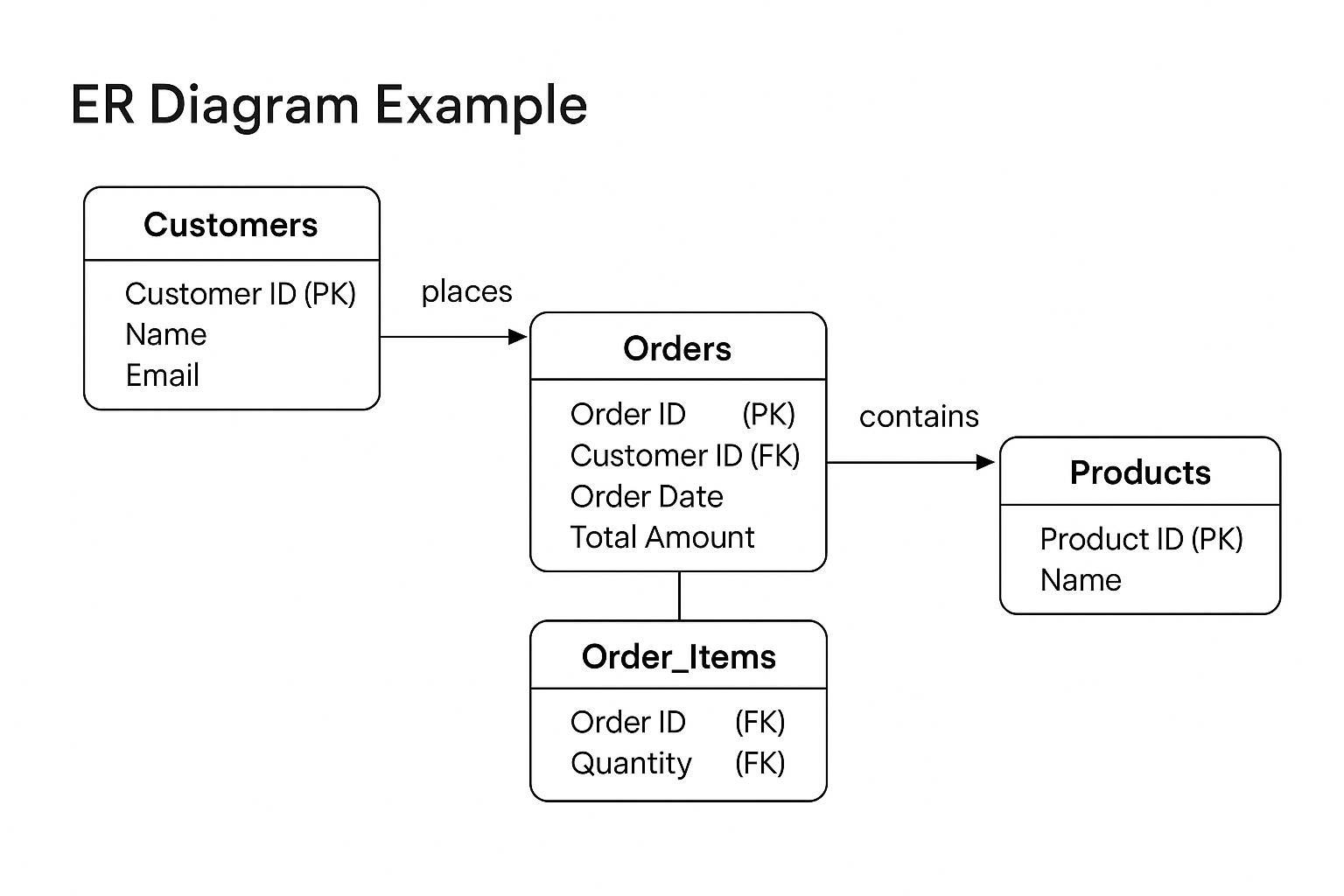
Example 1 Simple order management
Tables
- Customers CustomerID, Name, Email, Phone, Status
- Products ProductID, Name, SKU, Price, Active
- Orders OrderID, CustomerID, OrderDate, Status, Total
- OrderItems OrderItemID, OrderID, ProductID, Qty, UnitPrice
Relationships
- Customers 1 to many Orders
- Orders 1 to many OrderItems
- Products 1 to many OrderItems
Example 2 Project management with assignments
- Users UserID, Name, Email
- Projects ProjectID, Name, ClientID, Status
- Tasks TaskID, ProjectID, Title, Status, DueDate
- ProjectMembers ProjectMemberID, ProjectID, UserID, Role
Example 3 Multi location business with role based access
- Locations LocationID, Name, Region, Active
- Employees EmployeeID, LocationID, Name, Title
- Roles RoleID, RoleName
- EmployeeRoles EmployeeRoleID, EmployeeID, RoleID
How to design it in Tadabase
If you already understand tables and relationships, building in Tadabase is straightforward. You are translating standard relational design into a visual builder.
1 Create your tables
Start with core entities. Keep each table focused. In Tadabase, these are your data tables.
2 Add fields with the workflow in mind
Add only what you need to run the workflow and support the reports you know you will need. You can always add fields later without breaking the design.
3 Create connections between tables
Connections are how you model one to many and many to many relationships. For many to many, create a join table and connect it to both sides.
Related docs: Creating and managing data tables, Creating and managing fields, Getting started with connections.
4 Build pages and forms around the design
Good database design makes UI easier: a customer detail page can show orders, invoices, and tickets because the relationships are clean.
5 Add permissions and automation after structure is correct
Permissions and automation are where a shaky design hurts you. Get structure right first, then layer on workflows using: automations, Pipes, and Databridge.
If you want a fast start, begin with a template and adjust the schema to match how your business actually works.
Start a free trial and build your first schema in minutes.
Frequently Asked Questions
What are the main phases of database design
Most teams think in three layers: conceptual (what entities exist and how they relate), logical (tables, fields, keys, normalization), and physical (how it is implemented in a specific database with data types and performance choices).
What is the difference between a database schema and database design
Database design is the process and decisions. A schema is the resulting structure: tables, fields, keys, and relationships.
What is an ER diagram
An ER diagram is a visual map of entities and relationships. It helps you validate relationships before building and makes changes easier to communicate.
How do I know if I should normalize or denormalize
Normalize when you are duplicating a fact and updates can drift. Denormalize only when you have a clear reason (often reporting or performance), and keep one true source of truth.
What is the most common database design mistake
Many to many relationships modeled incorrectly. If you are trying to store multiple IDs in one field, you almost always need a join table.
Can I build a real database without coding
Yes, if the platform supports relational structure, relationships, permissions, and automation. Tadabase is built for that style of app building, especially when you need portals and workflow, not just a spreadsheet.


